Gen AI
虽然 LLM 提供了很大的潜力,但你也应该谨慎。
LLM 的核心是经过训练来预测序列中的以下单词。
这些单词基于训练数据中其他文本的模式和关系。这些训练数据的来源通常是互联网、书籍和其他公开可用的文本。这些数据的质量可能有问题,也可能是不正确的。培训发生在某个时间点,它可能无法反映世界的当前状态,也不会包含任何私人信息。
LLM 经过微调以尽可能有用,即使这意味着偶尔会产生误导性或毫无根据的内容,这种现象称为幻觉。
例如,当被要求“描述月亮”时,LLM可能会回答“月亮是由奶酪制成的”。虽然这是一句俗语,但事实并非如此。

修复幻觉
提供额外的上下文数据有助于为 LLM 的响应奠定基础并使其更加准确。
知识图谱是一种向 LLM 提供额外数据的机制。知识图谱中的数据可以指导 LLM 提供更相关、更准确和更可靠的响应。
虽然LLM使用其语言技能来解释和响应上下文数据,但它不会忽视原始训练数据。
您可以将原始训练数据视为基础知识和语言能力,而上下文信息则在特定情况下提供指导。
这两种方法的结合使 LLM 能够产生更有意义的响应。
避免幻觉
LLM 可以“编造”。LLM 旨在根据它们在大量数据中识别的模式生成类似人类的文本。
由于对模式的依赖和大量的训练信息,LLM有时会产生幻觉或产生输出,表现为产生不真实的事实,以毫无根据的信心断言细节,或制作合理但荒谬的解释。
这些表现形式源于过度拟合、训练数据中的偏差以及模型试图从大量信息中泛化。
常见的幻觉问题
让我们仔细看看发生这种情况的一些原因。
温度
LLM 有一个温度,对应于基础模型在生成文本时应使用的随机量。
温度值越高,生成的结果就越随机,响应就越有可能包含错误陈述。
在配置 LLM 以响应更多样化和创造性的输出时,更高的温度可能是合适的,但它是以牺牲一致性和精度为代价的。
例如,较高的温度可能适合构建小说作品或小说笑话。
另一方面,当基于事实的响应至关重要时,甚至需要较低的温度。0
考虑正确的温度
2023 年 6 月,美国法官制裁了两名美国律师,因为他们提交了一份由 LLM 生成的法律摘要,其中包含六份虚构的案例引文。
一个快速的解决方法可能是降低温度。但更有可能的是,LLM是幻觉,因为它没有得到所需的信息。
缺失信息
LLM 的训练过程错综复杂且耗时,通常需要长时间编译大量数据集。因此,这些模型可能缺乏最新信息,或者可能会错过在其训练数据中没有很好地表示的特定利基主题。
例如,如果一个法学硕士的最后一次更新是在 2022 年 9 月,它将不知道该日期之后发生的世界事件或各个领域的进步,导致其知识或反应的潜在差距似乎与当前现实脱节。
如果用户对难以找到的信息或公共领域之外的信息提出问题,LLM几乎不可能做出准确的回答。
幸运的是,这就是来自数据源(如知识图谱)的事实信息可以提供帮助的地方。
模型训练和复杂性
大型语言模型 (LLM) 通常被认为是“黑匣子”,因为难以破译其决策过程。

这些模型的复杂性,加上对错误或误导性数据的潜在训练,意味着它们的输出有时可能是不可预测的或不准确的。
例如,当被问及有争议的历史事件时,LLM可能会产生有偏见或不正确的答案。
此外,几乎不可能追溯该模型是如何得出这一结论的。法学硕士也无法提供其输出的来源或解释其推理。
提高 LLM 准确性
可以使用以下方法帮助指导 LLM 生成更一致和准确的结果。
提示工程
提示工程正在开发具体和深思熟虑的指令,以指导 LLM 朝着所需的响应方向发展。
通过改进指令的提出方式,开发人员无需重新训练即可从现有模型中获得更好的结果。
例如,如果你需要一篇博文摘要,而不是问“这篇博文是关于什么的?”,更合适的回答是“为这篇博文提供一个简洁的三句话摘要和三个标签”。
还可以包含“以 JSON 格式返回响应”,并提供示例输出,以便更轻松地使用所选的编程语言进行分析。
在问题中提供额外的说明和上下文称为零样本学习。
保持积极的态度
在编写提示时,旨在提供积极的指示。
例如,当要求专家提供描述时,您可以说:“不要使用复杂的词语。但是,专家对复合体的解释可能与您不同。相反,说,“使用简单的词,例如……”。这种方法提供了明确的说明和具体的例子。
情境学习
情境学习为模型提供了示例,以告知其响应,帮助它更好地理解任务。
该模型可以通过提供相关示例来提供更准确的答案,特别是对于利基或专业任务。
示例可能包括:
提供额外的背景信息 -When asked about “Bats”, assume the question is about the flying mammal and not a piece of sports equipment.
提供典型输入的示例 -Questions about capital cities will be formatted as “What is the capital of {country}?”
提供所需输出的示例 -When asked about the weather, return the response in the format “The weather in {city} is {temperature} degrees Celsius.”
为特定任务提供相关示例是 Few-shot 学习的一种形式。
微调
微调涉及在主要训练阶段之后,在较小的特定于任务的数据数据集上进行额外的语言模型训练。这种方法允许开发人员针对特定领域或任务专门化模型,从而提高其准确性和相关性。
例如,对特定业务的现有模型进行微调将增强其响应客户查询的能力。
这种方法是最复杂的,涉及技术知识、领域专业知识和高计算量。
一种更直接的方法是通过提供提示信息来使模型接地。
接地
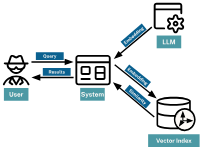
接地允许语言模型引用外部的最新源或数据库来丰富响应。
通过集成实时数据或 API,开发人员可以确保模型保持最新状态,并在最后一次训练截止时间之后提供事实信息。
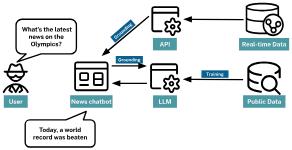
例如,如果为一家新闻机构构建一个聊天机器人,而不是仅仅依靠模型的最后训练数据,接地可以允许模型从新闻API中提取实时标题或文章。当用户问“奥运会的最新消息是什么?”时,聊天机器人可以通过接地提供最新文章的当前标题或摘要,确保响应及时准确。
数据截止日期
训练大型语言模型的计算成本很高。根据维基百科,OpenAI 的 GPT-3 模型在 1750 亿个参数上进行了训练,最终训练的模型需要 800GB 的存储空间。
在新数据上重新训练模型既昂贵又耗时。模型可能需要数周或数月的时间来训练。
提供快速发展的突发新闻的实时更新是不可能的。
检索增强生成
新闻机构可以在静态数据上训练模型,并用从最新来源检索的实时数据来补充预先存在的知识库。
这种方法称为检索增强生成(RAG)
RAG 将大规模语言模型的优势与外部检索或搜索机制相结合,使来自大量数据集的相关信息能够在生成过程中动态输入到模型中,从而增强其提供详细且上下文准确的响应的能力。
总之,通过添加来自其他数据源的内容,可以改进 LLM 生成的响应。
RAG的好处
RAG 的主要优点是提高了准确性。通过从外部特定领域的来源动态提取信息,RAG 基于的响应可以提供比独立的 LLM 更详细和上下文准确的答案。
RAG 提供以下额外优势:
提高透明度,因为可以存储和检查信息来源。
安全性,因为数据源可以得到保护和访问控制。
准确性和及时性,因为数据源可以实时更新。
访问私人或专有数据
输入数据坏,数据输出坏
当提示 LLM 根据提供的上下文进行响应时,答案将始终与提供的上下文一样好。
如果您的提示建议将菠萝作为披萨配料,那么如果它建议您订购夏威夷披萨,请不要感到惊讶。
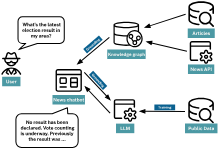
RAG可以通过以下方式支持新闻机构聊天机器人:
访问实时新闻提要
从数据库中提取最近的头条新闻或新闻文章,
为LLM提供这个额外的背景
存储在知识图谱中的新闻文章将是此用例的理想选择。知识图谱可以传递有关所涉及的实体与文章元数据之间关系的 LLM 详细信息。
例如,当询问最近的选举结果时,这些知识可以提供有关候选人的额外背景、与他们相关的新闻报道或来自同一作者的有趣文章。
向量和语义搜索
RAG 的挑战之一是了解用户的要求并显示正确的信息以传递给 LLM。
语义搜索与传统关键字搜索
语义搜索旨在了解搜索短语的意图和上下文含义,而不是专注于单个关键字。
传统的关键字搜索通常依赖于精确匹配的关键字或基于邻近度的算法来查找相似的单词。
例如,如果您在传统搜索中输入“苹果”,则可能主要获得有关水果的结果。
然而,在语义搜索中,引擎试图衡量上下文:你是在搜索水果、科技公司还是其他什么?
结果是根据术语和感知意图量身定制的。
向量和嵌入
在自然语言处理 (NLP) 和机器学习中,数字表示(称为向量)表示单词和短语。
向量中的每个维度都可以表示单词或短语的特定语义方面。当多个维度结合在一起时,它们可以传达单词或短语的整体含义。
向量不会直接编码有形属性,如颜色、味道或形状。 相反,该模型将生成一个数值列表,使该词与相关词(如健康、营养和保健)紧密对齐。
在搜索上下文中应用时,“apple”的向量可以与其他单词或短语的向量进行比较,以确定最相关的结果。
您可以通过多种方式创建向量,但最常见的方法之一是使用大型语言模型。这些向量称为嵌入。对于高级模型,这些嵌入还包含上下文信息。
单词的向量可以根据其周围的上下文而变化。例如,单词 bank 在 River bank 中的向量与在 Savings bank 中的向量不同。
语义搜索系统可以使用这些上下文嵌入来理解用户意图。
您可以使用向量之间的距离或角度来衡量单词或短语之间的语义相似性。

具有相似含义或上下文的单词将具有靠近的向量,而不相关的单词将相距较远。
此原则用于语义搜索,以查找用户查询的上下文相关结果。
语义搜索包括以下步骤:
用户提交查询。
系统创建查询的向量表示形式(嵌入)。
系统将查询向量与索引数据的向量进行比较。
根据结果的相似性对结果进行评分。
系统将最相关的结果返回给用户。