
网络编程模型
网络编程模型
网络编程模型的核心:
服务器如何管理连接
服务器如何处理请求
以上两个设计点最终都和操作系统的 I/O 模型及进程模型相关
I/O模型:阻塞 、非阻塞、同步 、异步
进程模型:单进程、 多进程、多线程
PPC (Process per Connection)
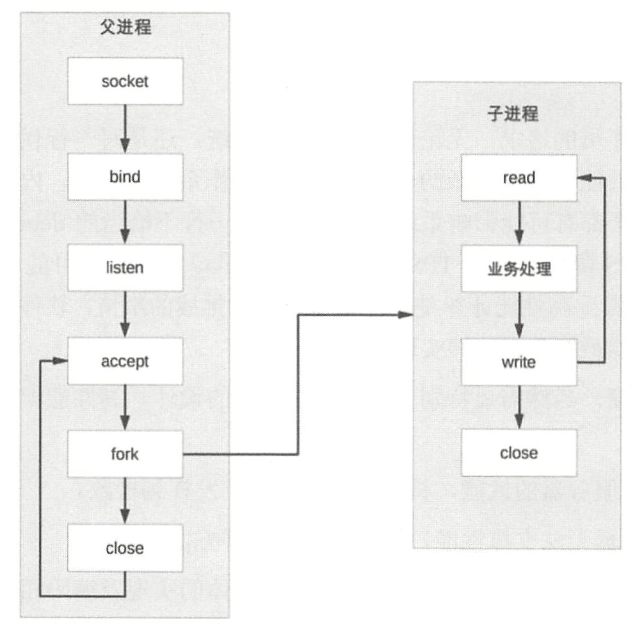
- 父进程接受连接(图中accept)
- 父进程“fork”子进程(图中fork)
- 子进程处理连接的读写请求(图中子进程read、业务处理、write)
- 子进程关闭连接(图中子进程中的close)
PPC 模式实现简单,比较适合服务器的连接数没那么多的情况(eg. pgsql)
而互联网兴起后,服务器的并发和访问量从几十剧增到成千上万,这种模式的弊端就凸显出来了,主要体现在如下几个方面:
- fork代价高:站在操作系统的角度,创建一个进程的代价是很高的,需要分配很多内核资源,需要将内存映像从父进程复制到子进程。
- 父子进程通信复杂:父进程“fork”子进程时,文件描述符可以通过内存映像复制从父进程传到子进程,但“fork”完成后,父子进程通信就比较麻烦了,需要采用IPC(InterprocessCommunication)之类的进程通信方案。
- 进程数量增大后对操作系统压力较大:如果每个连接存活时间比较长,而且新的连接又源源不断的进来,则进程数量会越来越多,操作系统进程调度和切换的频率也越来越高,系统的压力也会越来越大。
因此,一般情况下,PPC方案能处理的并发连接数量最大也就几百。
针对PPC模式不同的缺点,产生了不同的解决方案
prefofk 提前创建进程
省去“fork”进程的操作,让用户的访问更快、体验更好
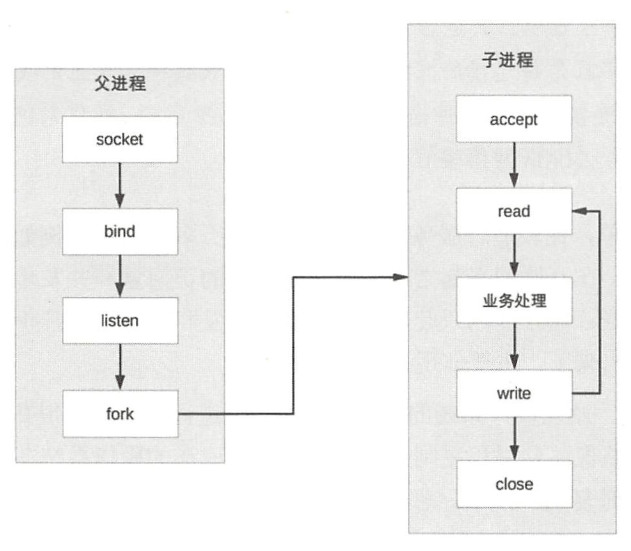
prefork的实现关键就是多个子进程都accept同一个socket,当有新的接进入时,操作系统保证只有一个进程能最后accept成功
prefork模式和PPC一样,还是存在父子进程通信复杂、支持的并发连接数量有限的问题
TPC (Thread per Connection)
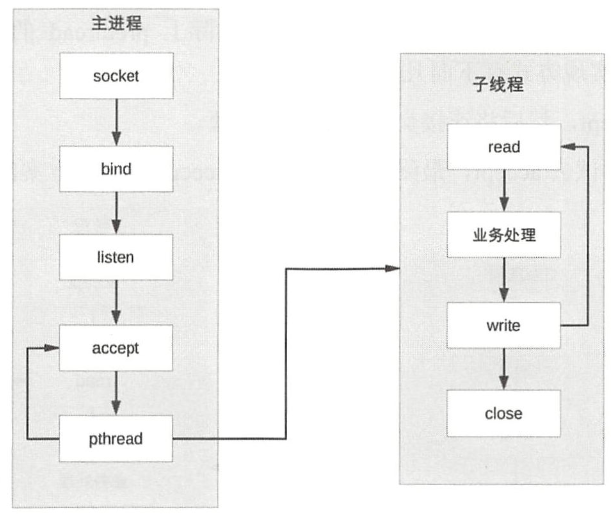
- 父进程接受连接(图中accept)
- 父进程创建子线程(图中pthread)
- 子线程处理连接的读写请求(图中子线程read、业务处理、rite)
- 子线程关闭连接(图中子线程中的close)
TPC虽然解决了fork代价高和进程通信复杂的问题,但是也引入了新的问题:
- 创建线程虽然比创建进程代价低,但并不是没有代价,高并发时(例如每秒上万连接)还是有性能问题
- 无须进程间通信,但是线程间的互斥和共享又引入了复杂度,可能一不小心就导致了死锁问题
- 多线程会出现互相影响的情况,某个线程出现异常时,可能导致整个进程退出(例
如内存越界) - TPC还是存在CPU线程调度和切换代价的问题。
因此,TPC方案本质上和PPC方案基本类似,在并发几百连接的场景下,反而更多的是采用PPC的方案,因为PPC方案不会有死锁的风险,也不会多进程互相影响,稳定性更高。
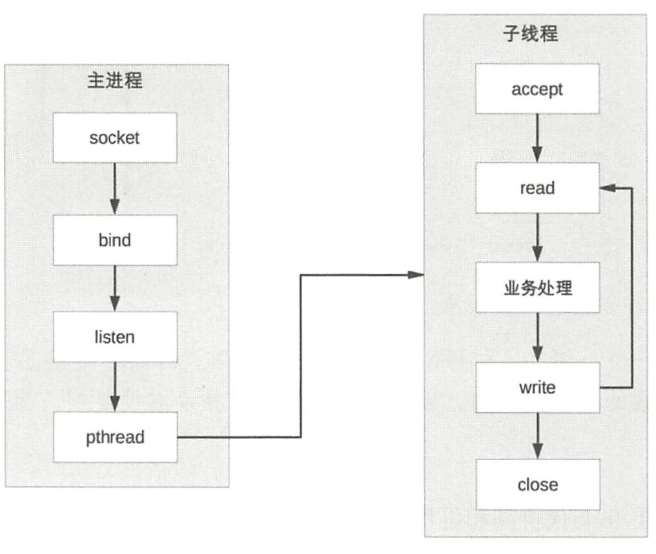
prethread 预先创建线程,省去创建线程的操作
实现方式:
- 主进程accept,然后将连接交给某个线程处理。
- 子线程都尝试去accept,最终只有一个钱程accept成功
Reactor 非阻塞同步网络模型模型
下面就是大名鼎鼎的、厉害得不得了的 Reactor 模型!!!
PPC方案最主要的问题就是每个连接都要创建进程(以PPC和进程为例,换成TPC和线程,原理是一样的),连接结束后进程就销毁了,这样做其实是很大的浪费。为了解决这个问题,一个自然而然的想法就是资源复用,即不再单独为每个连接创建进程,而是创建一个进程池,将连接分配给进程,一个进程可以处理多个连接的业务。
引入资源池的处理方式后,会引出一个新的问题:进程如何才能高效地处理多个连接的业务?当一个连接一个进程时,进程可以采用“read->业务处理->write”的处理流程,如果当前连接没有数据可以读,则进程就阻塞在read操作上。这种阻塞的方式在一个连接一个进程的场景下没有问题,但如果一个进程处理多个连接,进程阻塞在某个连接的read操作上,此时即使其他连接有数据可读,进程也无法去处理,很显然这样是无法做到高性能的。
解决这个问题的最简单的方式是将 read 操作改为非阻塞,然后进程不断地轮询多个连接。
这种方式能够解决阻塞的问题,但解决的方式并不优雅。首先轮询是要消耗 CPU 的;其次如果一个进程处理几千上万的连接,则轮询的效率是很低的。
为了能够更好地解决上述问题,一种自然而然的想法就是只有当连接上有数据的时候进程才去处理,这就是 I/O 多路复用技术的来源。
I/O 多路复用技术归纳起来有如下两个关键实现点:
- 当多条连接共用一个阻塞对象后,进程只需要在一个阻塞对象上等待,而无须再轮询所有连接。
- 当某条连接有新的数据可以处理时,操作系统会通知进程,进程从阻塞状态返回,开始进行业务处理。
Reactor:即I/O多路复用统一监昕事件,收到事件后分配(Dispatch)给某个进程
Reactor模式的具体实现方案灵活多变,主要体现在如下两点
- Reactor的数量可以变化:可以是一个Reactor,也可以是多个Reactor
- 资源池的数量可以变化:以进程为例,可以是单个进程,也可以是多个进程(线程类似)
单 Reactor 单进/线程
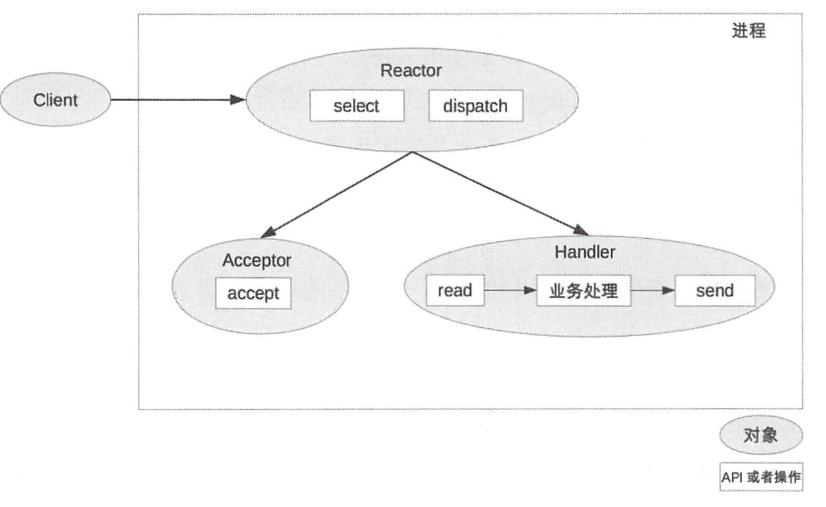
- Reactor对象通过select监控连接事件,收到事件后通过dispatch进行分发。
- 如果是连接建立的事件,则由Acceptor处理,Acceptor通过accept接受连接,并创
- 建一个Handler来处理连接后续的各种事件。
- 如果不是连接建立事件,则Reactor会调用连接对应的Handler(第2步中创建的Handler)来进行响应。
- Handler会完成read->业务处理->send的完整业务流程。
单Reactor单进程的模式优点就是很简单,没有进程间通信,没有进程竞争,全部都在同一个进程内完成。但其缺点也是非常明显,具体表现如下:
- 只有一个进程,无法发挥多核CPU的性能;只能采取部署多个系统来利用多核CPU,但这样会带来运维复杂度,本来只要维护一个系统,用这种方式需要在一台机器上维护多套系统。
- Handler在处理某个连接上的业务时,整个进程无法处理其他连接的事件,很容易导致性能瓶颈。
因此,单Reactor单进程的方案在实践中应用场景不多,只适用于业务处理非常快速的场景,目前比较著名的开源软件中使用单Reactor单进程的是Redis。
单 Reactor 多线程(不是多进程)
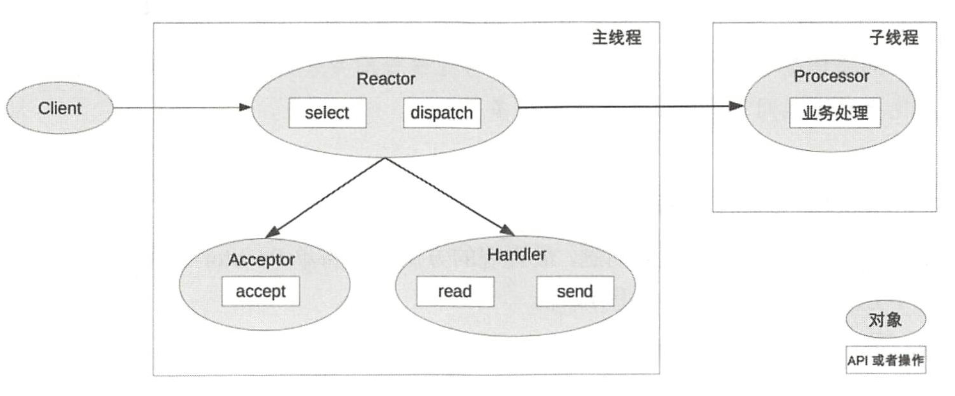
- 主线程中,Reactor对象通过select监控连接事件,收到事件后通过dispatch进行分发。
- 如果是连接建立的事件,则由Acceptor处理,Acceptor通过accept接受连接,并创建一个Handler来处理连接后续的各种事件。
- 如果不是连接建立事件,则Reactor会调用连接对应的Handler(第2步中创建的Handler)来进行响应。
- Handler只负责响应事件,不进行业务处理;Handler通过read读取到数据后,会发给Processor进行业务处理。
- Processor会在独立的子钱程中完成真正的业务处理,然后将响应结果发给主进程的Handler处理;Handler收到响应后通过send将响应结果返回给client。
单Reactor多线程方案能够充分利用多核多CPU的处理能力,但同时也存在如下问题:
- 多线程数据共享和访问比较复杂。例如,子线程完成业务处理后,要把结果传递给主线程的Reactor进行发送,这里涉及共享数据的互斥和保护机制。以Java的NIO为例,Selector是线程安全的,但是通过elector.selectKeys()返回的键的集合是非线程安全的,对selectedkeys的处理必须单线程处理或采取同步措施进行保护。
- Reactor承担所有事件的监昕和响应,只在主线程中运行,瞬间高并发时会成为性能瓶颈。
多 Reactor 多进程/线程
为了解决单 Reactor 多线程的问题,最直观的方法就是将单 Reactor 改为多 Reactor ,这就产生了第三个方案:
多Reactor多进程/线程!
多Reactor多进程/线程方案示意图如下(以进程为例)
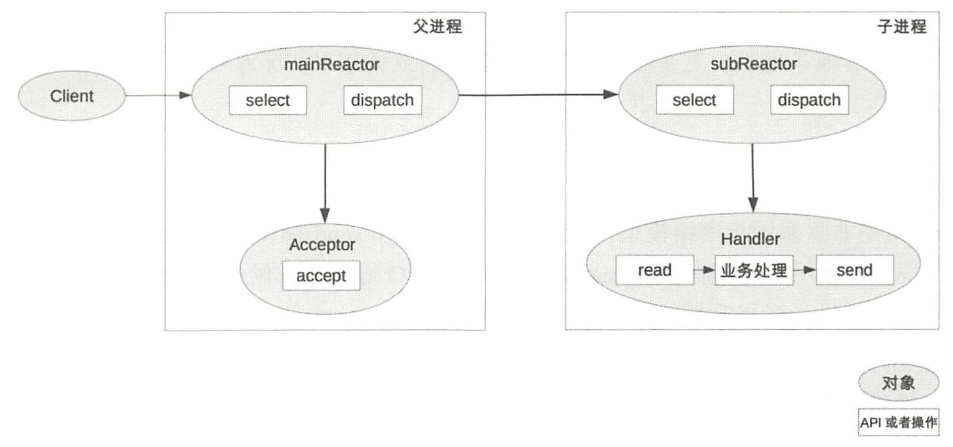
方案详细说明如下:
- 父进程中mainReactor对象通过select监控连接建立事件,收到事件后通过Acceptor接收,将新的连接分配给某个子进程。
- 子进程的subReactor将mainReactor分配的连接加入连接队列进行监听,并创建一个Handler用于处理连接的各种事件。
- 当有新的事件发生时,subReactor会调用连接对应的Handler(即第2步中创建的Handler)来进行响应。
- Handler完成read -> 业务处理 -> send的完整业务流程。
多Reactor多进程/线程的方案看起来比单Reactor多线程要复杂,但实际实现时反而更加简单,主要原因如下:
- 父进程和子进程的职责非常明确,父进程只负责接收新连接,子进程负责完成后续的业务处理。
- 父进程和子进程的交互很简单,父进程只需要把新连接传给子进程,子进程无须返回数据。
- 子进程之间是互相独立的,无须同步共享之类的处理(这里仅限于网络模型相关的select、read、send等无须同步共享,“业务处理”还是有可能需要同步共享的)。
目前采用多Reactor多进程实现的著名的开源系统是Nginx,采用多Reactor多线程实现有Memcache和Netty.
Proactor 非阻塞异步网络模型
接下来就是举世闻名的、牛逼得不得了的 Proactor 模型!!!
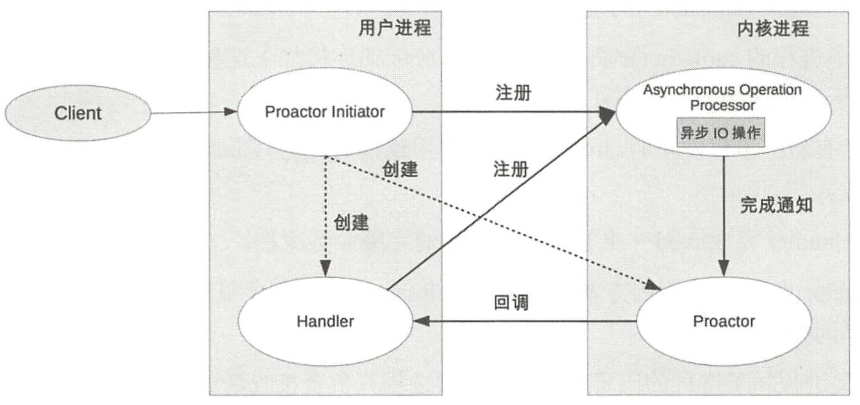
方案详细说明如下:
- ProactorInitiator负责创建Proactor和Handler,并将Proactor和Handler都通过As归chronousOperationProcessor注册到内核。
- AsynchronousOperationProcessor负责处理注册请求,并完成1/0操作。
- AsynchronousOperationProcessor完成I/O操作后通知Proactor。
- Proactor根据不同的事件类型回调不同的Handler进行业务处理。
- Handler完成业务处理,Handler也可以注册新的Handler到内核进程。
理论上Proactor比Reactor效率要高一些,异步I/O能够充分利用DMA特性,让I/O操作与计算重叠。
但实现真正的异步I/O,操作系统需要做大量的工作,目前Windows下通过IOCP实现了真正的异步I/O,
而在Linux系统下的AIO并不完善,因此在Linux下实现高并发网络编程时都是以Reactor模式为主